Spring知识点梳理
Spring IoC
IoC简介
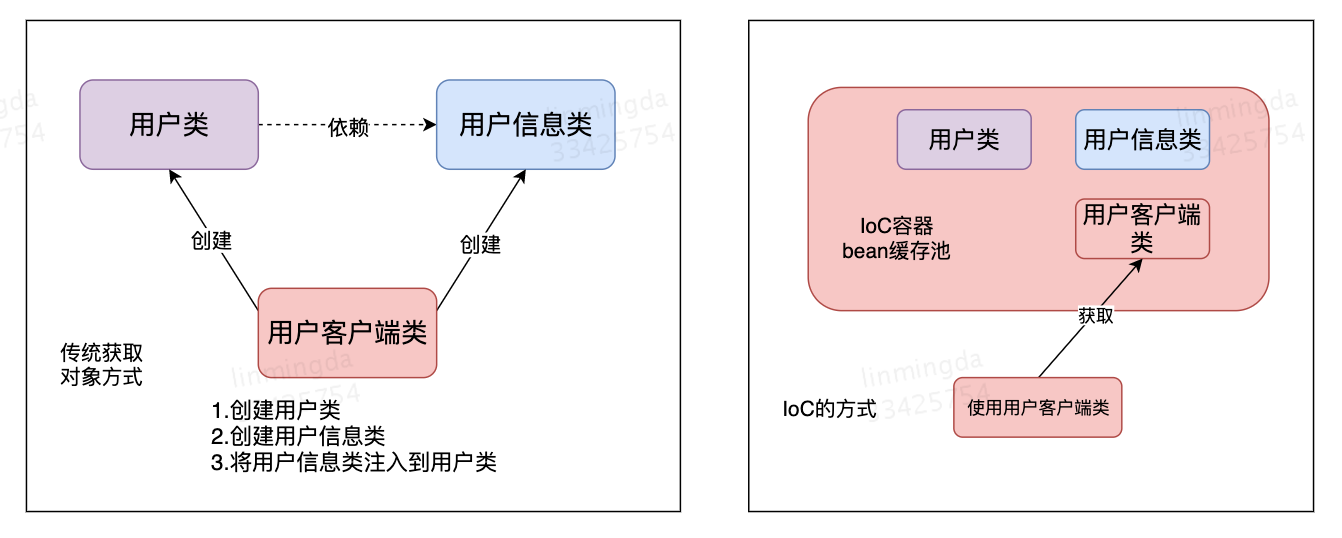
IoC:控制反转(Inversion of Control)容器,是一种设计思想。它意味着将对象交给容器控制,而不是开发者在对象内部控制。IoC是通过DI来实现的。
谁控制谁?IoC容器来控制对象。
控制什么?控制了外部资源获取(不只是对象包括比如文件等)
为什么是反转?因为由容器帮我们查找及注入依赖对象,对象只是被动的接受依赖对象,所以是反转。
什么被反转了?依赖对象的获取被反转了。
DI:依赖注入(Dependency Injection),组件之间依赖关系由容器在运行期决定,即由容器动态的将某个依赖关系注入到组件之中。IoC和DI其实是同一个概念的不同角度描述。
DI是通过IoC容器来实现的。
IoC容器
Spring的两种容器
IoC容器本质是一个工厂。Spring主要提供了两种类型的容器。
BeanFactory
BeanFactory是IoC容器的顶层接口,ApplicationContext是在BeanFactory之上创建的。
BeanFactory一般采用延迟初始化的策略。只有当客户端访问容器里的对象的时候,才对对象进行初始化和依赖注入。因此容器启动初期速度较快。
ApplicationContext
ApplicationContext 在BeanFactory功能至上,还有事件发布等功能。
ApplicationContext 在容器启动时就完成所有对象的初始化,因此启动需要的资源多,启动慢。
Ioc容器的初始化过程(Bean的加载过程)
获取资源;
获取BeanFactory;
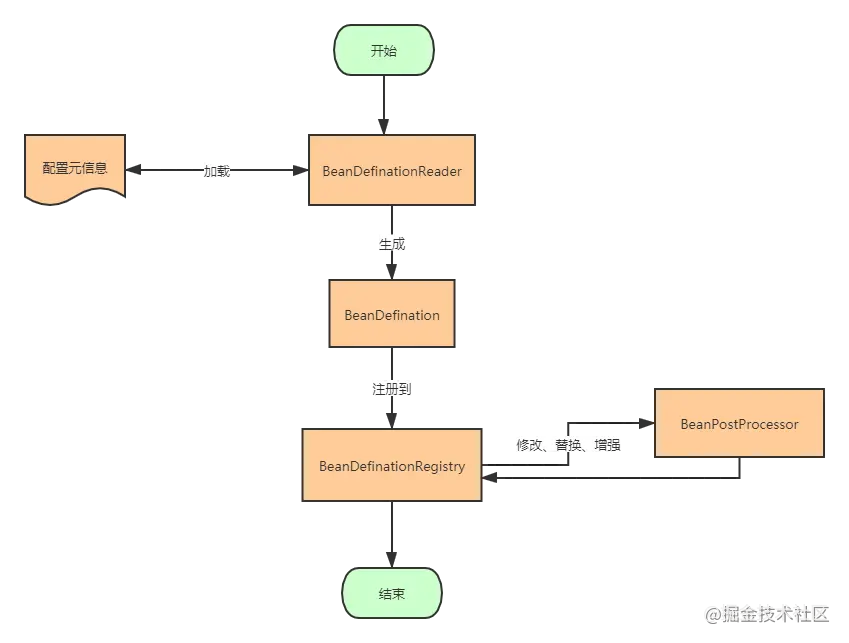
根据BeanFactory创建BeanDefinitionReader对象,该Reader对象作为资源的解析器;
装载资源;
- 资源定位:通过ResourceLoader加载外部资源,通过外部资源描述Bean对象
- 加载:通过资源解析器(BeanDefinitionReader)解析外部资源(Resource),封装成一个BeanDefiniton对象;
- 注册:通过实现BeanDefinitionRegistry接口,将BeanDefinition注入到Map容器中;
Bean的实例化过程(Bean的生命周期)
Bean的实例化过程分为两个阶段:1、容器启动阶段;2、Bean的实例化阶段。Bean的整个生命周期体现在实例化阶段。
在容器启动阶段,要完成bean在Ioc容器的注册。Spring是通过BeanDefinitionReader将对象配置信息转换成BeanDefinition存在BeanDefinationRegistry里的HashMap容器(BeanDefinition是在IoC容器里对bean的封装)
bean的生命周期``AbstractAutowireCapableBeanFactory.doCreateBean()`
- 实例化
createBeanInstance(): 该过程会返回一个BeanWrapper对象,是一个没有注入属性的裸露的bean- 如果存在 Supplier回调,则从Supplier进行初始化(Supplier是一个泛型接口,在构造BeanDefinition的时候会进行设置,用于指定创建bean的回调,指定后其他构造器和工厂方法都会没用);
- 如果存在工厂方法,则使用工厂方法进行初始化
- 首先判断缓存,如果缓存中有解析过的构造函数,则用解析过的构造函数进行实例化;
- 如果缓存中没有,通过
SmartInstantiationAwareBeanPostProcessor(BeanPostProcessor的子类)到构造器列表,进行实例化。
- 注入属性
populateBean():将 BeanDefinition 中的属性值赋值给 BeanWrapper 实例对象- 在注入属性的时候可以按照名称注入,也可以按照类型注入;二者会统一注入到PropertyValues中;再将PropertyValues填充到BeanWrapper中。
- 初始化
initializeBean()- 激活
Aware方法(实现了Aware接口的方法可以通过Spring回调接受Spring容器的通知)- 通过BeanNameAware可以注入名称属性;
- 通过BeanClassLoaderAware可以注入类加载器属性;
- 通过BeanFactoryAware可以注入工厂属性;
- 后置处理器应用
- 比如在AOP中利用后置处理器进行增强操作
- 激活自定义的
init方法- 自定义初始化方法可以是通过实现InitializingBean接口,进行初始化
- 还可以使用init-method解析配置文件进行初始化
- 激活
- 销毁

Bean的管理
Spring通过Ioc容器对Bean进行管理。可以通过注解或者xml文件的方式进行配置。
管理Bean常用的注解:
@ComponentScan用于声名扫描Bean的策略,对哪些包哪些类型的Bean进行扫描;@Component``Repository``Service``Controller用于声明Bean;@Autowired``@Qualifier用于注入Bean;Autowired按照Bean的类型进行匹配,如果同一类型的Bean有多个,可以通过@Qualifier按Bean的名称进行匹配;@Scope用于声明Bean的作用域,Bean默认是单例的PostConstruct``PreDestory用于声明Bean的生命周期,PostConstruct在Bean初始化后调用,PreDestory在销毁Bean之前调用;
问题整理
依赖注入的三种方式?
Spring是如何解决循环依赖的?
Spring解决单例对象setter注入原理
Spring只能解决setter方法注入的单例对象的循环依赖问题。(构造器注入的方式已经在调用构造器构建bean的时候注入好了,而非单例的对象都是)
三级缓存:
- 一级缓存
SingletonObjects存的是已经初始化完成的bean - 二级缓存
earlySingletonObjects缓存的是提前曝光的bean,但是还没有完成初始化 - 三级缓存
SingletonFactories存的是函数接口beanfactory,而非bean实例,提供一个提前引用
调用构造器构建对象 > 实例化 > 三级缓存 >注入属性 > 二级缓存 > 初始化 > 一级缓存 > 完成
为什么是三级缓存,不是一级、二级缓存?
一级缓存:要缓存正在实例化阶段但未完成初始化的bean,但这种情况只能解决单线程的循环依赖问题,在多线程环境下,线程可能通过缓存获得未注入属性的bean;
二级缓存:将初始化完成的bean设为一级缓存,将正在实例化阶段但未初始化的bean设为二级缓存,这种情况是可以解决没有AOP场景下的循环依赖的。
三级缓存:对于有AOP的场景,在通过beanFactory获取代理对象的时候,为了保证生成的代理对象是单例的,需要再在中间加一层缓存,去查二级缓存的代理对象。
BeanFactory和ApplicationContext的区别?
1、加载策略:BeanFactory采用的是延迟加载策略,使用到某个bean的时候才会对bean进行实例化,而ApplicationContext是在容器启动时,一次性创建所有的bean;
2、对BeanPostProcessor的支持:BeanFactory需要手动注册(调用addBeanPostProcessor()方法),而ApplicationContext是自动注册;
3、BeanFactory面对的是Spring框架,ApplicationContext主要面对开发者,提供了更多的扩展功能(事件发布、国际化信息),因此开发尝试用的容器是ApplicationContext。
BeanFactory继承关系
BeanFactory是一个一级接口,继承BeanFactory的二级接口有三个,分别是ListableBeanFactory、HierarchicalBeanFactory、AutowireCapableBeanFactory。
- ListableBeanFactory:将bean列表化,不需要单个的获取bean,提供了如根据类型、注解获取beanNames的方法;
- HierarchicalBeanFactory:表示bean有继承关系,可以获取父类BeanFactory的方法;
- AutowireCapableBeanFactory:定义bean的自动装配规则,提供了bean创建、配置、注入、销毁等操作。
对于后面的实现子类有一个比较重要的是AbstractAutowireCapableBeanFactory,该实现类用于bean的实例化。
创建对象的策略
“策略模式”的实例化方式的选取策略:根据用户是否使用replace或lookup的配置方法,如果没有使用,用反射创建,否则用CGLIB。参考
附:概念解释
BeanWrapper
BeanWrapper 是实例化后的Bean实例,相当于一个代理类,spring委托BeanWrapper进行属性填充。
Aware接口
Aware接口是Spring提供的一个标识接口,Spring 容器在初始化主动检测当前 bean 是否实现了 Aware 接口,如果实现了则回调(invokeAwareMethods)其 set 方法将相应的参数 (比如beanName、beanClassLoader、BeanFactory 等)设置给该 bean 。
Aware接口就是在bean初始化的时候为bean注入属性的。
BeanPostProcessor
BeanPostProcessor是一个接口,实现了该接口的bean在初始化前后可以通过BeanPostprocessor进行一些配置和增加一些处理逻辑。
BeanPostProcessor会根据容器注册,注册完后会应用于同一容器内的bean。ApplicationContext 会自动检测所有实现了 BeanPostProcessor 接口的 bean,并完成注册,但是使用 BeanFactory 容器时则需要手动调用 addBeanPostProcessor() 完成注册。
BeanPostProcessor的原理:1、对于BeanFactory容器来说,在bean初始化的时候会分别调用BeanPostProcessor的前置处理方法和后置处理方法,在处理方法内部,会遍历Spring容器里完成注册的BeanPostProcessor,如果有,就调用处理方法去初始化一个增强的bean,否则直接初始化返回一个普通的bean。而注册BeanPostProcessor需要通过addBeanPostProcessor()方法完成,getBean()是不能注册BeanPostProcessor的;2、对于ApplicationContext容器来说,会通过调用registerBeanPostProcessors()自动检测BeanPostProcessor并注册到ApplicationContext容器中,同时应用到创建的bean中。
InitializingBean & init-method
bean在初始化阶段initializeBean调用后置处理器的前置后置方法中间,会调用invokeInitMethods()来检测bean是否实现了InitializingBean接口,如果实现了则进一步调用afterPropertiesSet()方法对bean对象的状态进行进一步的调整。
相对于initializeBean要bean实现方法, init-method只需要在xml配置文件中进行绑定,通过反射执行可以完成对象的状态更新。
Reference
- http://www.4k8k.xyz/article/weixin_38405253/116279890
- https://www.cmsblogs.com/article/1391375268060467200
- 《Spring5核心原理与30个类手写实战.pdf》
Spring AOP
AOP介绍
spring的AOP就是把切面(Advice、Advisor)织入(Weaving)到满足切点(PointCut)限定条件的连接点(JoinPoint)的过程。
所谓切面是通知和切点的结合,通常我们是面对切面进行编程的;通知是指切面对连接点的一组增强处理的操作;切点是匹配连接点的断言,通过切点表达式和通知相关联;连接点是指程序在执行时的行为,一般对应目标对象的方法。
Spring在Bean的创建过程中的初始化阶段的后置处理(BeanPostProcessor接口的postProcessAfterInitialization方法)的时候,在满足条件的情况下会对Bean进行AOP增强。
从代码实现上具体来说就是:Spring通过AbstractAutowireCapableBeanFactory抽象类对Bean进行创建和依赖注入。在该抽象类里实现了doCreateBean()方法,在该方法内部又是通过initializeBean()方法为Bean添加后置处理器(BeanPostProcessor)。
对于BeanPostProcessor接口的核心实现就是AbstractAutoProxyCreator的wrapIfNecessary方法(有不同子类的实现,以AbstractAutoProxyCreator为例)。该方法主要做的事情是,找到容器中能够应用到当前所创建的bean的切面,再利用切面为bean创建代理对象;在创建代理对象的时候,用的是代理工厂获取的代理对象(proxyFactory.getProxy()),在底层对于JDK代理对象还是CGLib代理对象的选择是通过DefaultAopProxyFactory的createAopProxy()方法判断的。
Spring在target实现了接口的情况下默认使用JDK动态代理;也可以通过配置强制使用CGLib;如果target没有实现接口,则使用CGLib。
InvocationHandler是JDK动态代理的核心,生成的代理对象的方法调用会委派到invoke()方法中去,因此Spring将切面织入连接点的核心逻辑是体现在invoke()方法中的。Spring实现invoke()方法的核心逻辑是,获取应用在此方法上的拦截器链(Interceptor Chain),如果有拦截器,则应用拦截器执行连接点;如果没有拦截器,则通过反射执行连接点。
拦截器链的获取是通过一个工厂方法(AdvisorChainFactory的getInterceptorsAndDynamicInterception-Advice()方法)完成的,该方法完成了两件事:1、将拦截器链进行缓存;2、得到一个拦截器列表(连接点(JoinPoint)或目标对象(Target)的通知(Advisor)都会转换成MethodInterceptor);在具体使用拦截器链的时候,通过创建一个MethodInocation对象,执行proceed()方法完成织入的。
参考资料
- 《Spring5核心原理与30各类手写实战.pdf》
- https://juejin.cn/post/6877137943149051911#heading-2
AOP & Spring AOP
AOP(Aspect oriented programming)面向切面编程,是OOP的一种补充。
OOP的一大特性——继承,体现了对象之间的“上下关系”,而AOP的切面之间则可以为分散的对象提供公共行为,是一种“左右关系”。
利用AOP可以为业务逻辑进行解耦,提高开发效率。
spring aop 有两种实现方式:
- JDK动态代理:这是Java提供的动态代理技术,可以在运行时创建接口的代理实例。Spring AOP默 认采用这种方式,在接口的代理实例中织入代码。
- CGLib动态代理:采用底层的字节码技术,在运行时创建子类代理的实例。当目标对象不存在接口时,Spring AOP就会采用这种方式,在子类实例中织入代码。

AOP术语
- 切面( Aspect): 切面是通知和切点的结合;对应Spring中的注解@Aspect修饰的一个类;可以由ApplicationContext中的
<aop:aspect>来配置; - 通知 (Advice): 指切面对连接点的操作,为AOP 框架中的增强处理。通知描述了切面何时执行以及如何执行增强处理;通知类型,主要有以下几种:
- Before :前置通知,在连接点方法前调用;对应Spring中@Before注解;
- After :后置通知,在连接点方法后调用;对应Spring中的@After注解;
- AfterReturning:返回通知,在连接点方法执行并正常返回后调用,要求连接点方法在执行过程中没有发生异常;对应Spring中的@AfterReturning注解;
- AfterThrowing:异常通知,当连接点方法异常时调用;对应Spring中的@AfterThrowing注解;
- Around:环绕通知,它将覆盖原有方法,但是允许你通过反射调用原有方法;对应Spring中的@Around注解;
- 切点(Pointcut): 匹配连接点的断言,通过一个切点表达式和通知关联;
- 连接点(JointPoint): 指程序执行过程中的某一行为,可以是方法的调用、异常的抛出。在 Spring AOP 中,连接点总是方法的调用,可以说目标对象中的方法就是一个连接点;
- 目标对象(Target object):即被代理的对象;
- 代理对象(AOP proxy):包含了目标对象的代码和增强后的代码的那个对象;
AOP实现原理
AOP的实现方式
AOP的实现核心在于如何把切面织入到核心业务逻辑中。Java提供了3种方式:
- 在编译期把切面编入到字节码,通过使用关键字来实现织入(AspectJ使用的是aspect关键字);
- 在目标类被装入JVM时,通过一个特殊的类加载器,对目标类的字节码重新“增强”;
- 在运行期通过JVM动态代理织入。
Spring采用动态代理方式实现AOP。当代理接口实现类的时候默认用JDK,代理普通类用CGLIB。
JDK实现
JDK的动态代理是基于反射实现。JDK通过反射,生成一个代理类,这个代理类实现了原来那个类的全部接口,并对接口中定义的所有方法进行了代理。当我们通过代理对象执行原来那个类的方法时,代理类底层会通过反射机制,回调我们实现的InvocationHandler接口的invoke方法。并且这个代理类是Proxy类的子类(记住这个结论,后面测试要用)。这就是JDK动态代理大致的实现方式。
CGLIB实现
CGLib实现动态代理的原理是,底层采用了ASM字节码生成框架,直接对需要代理的类的字节码进行操作,生成这个类的一个子类,并重写了类的所有可以重写的方法,在重写的过程中,将我们定义的额外的逻辑(简单理解为Spring中的切面)织入到方法中,对方法进行了增强。而通过字节码操作生成的代理类,和我们自己编写并编译后的类没有太大区别。
Spring AOP的使用
问题整理
如何配置CGLIB生成代理?
前面说过Spring使用动态代理或是CGLIB生成代理是有规则的,高版本的Spring会自动选择是使用动态代理还是CGLIB生成代理内容,当然我们也可以强制使用CGLIB生成代理,那就是aop:config里面有一个”proxy-target-class”属性,这个属性值如果被设置为true,那么基于类的代理将起作用,如果proxy-target-class被设置为false或者这个属性被省略,那么基于接口的代理将起作用。
参考资料
- https://www.cnblogs.com/zyly/p/13171660.html
- https://www.cnblogs.com/joy99/p/10941543.html
- https://www.pdai.tech/md/spring/spring-aop.html
- https://tech.meituan.com/2019/09/05/java-bytecode-enhancement.html
Spring MVC
问题整理
MVC简介
SpringMVC执行流程
执行流程:
- 用户发送请求至前端控制器DispatcherServlet
- DispatcherServlet收到请求调用HandlerMapping处理器映射器
- 处理器映射器根据请求url找到具体的处理器,生成处理器对象及处理器拦截器(如果有则生成)一并返回给DispatcherServlet
- DispatcherServlet通过HandlerAdapter处理器适配器调用处理器
- 执行处理器(Controller,也叫后端控制器)
- Controller执行完成返回ModelAndView
- HandlerAdapter将controller执行结果ModelAndView返回给DispatcherServlet
- DispatcherServlet将ModelAndView传给ViewReslover视图解析器
- ViewReslover解析后返回具体View
- DispatcherServlet对View进行渲染视图(即将模型数据填充至视图中)
- DispatcherServlet响应用户

组件说明:
DispatcherServlet:前端控制器
用户请求到达前端控制器,它就相当于mvc模式中的c,dispatcherServlet是整个流程控制的中心,由它调用其它组件处理用户的请求,dispatcherServlet的存在降低了组件之间的耦合性。HandlerMapping:处理器映射器
HandlerMapping负责根据用户请求url找到Handler即处理器,springmvc提供了不同的映射器实现不同的映射方式,例如:配置文件方式,实现接口方式,注解方式等。Handler:处理器
Handler 是继DispatcherServlet前端控制器的后端控制器,在DispatcherServlet的控制下Handler对具体的用户请求进行处理。
由于Handler涉及到具体的用户业务请求,所以一般情况需要程序员根据业务需求开发Handler。HandlAdapter:处理器适配器
通过HandlerAdapter对处理器进行执行,这是适配器模式的应用,通过扩展适配器可以对更多类型的处理器进行执行。ViewResolver:视图解析器
View Resolver负责将处理结果生成View视图,View Resolver首先根据逻辑视图名解析成物理视图名即具体的页面地址,再生成View视图对象,最后对View进行渲染将处理结果通过页面展示给用户。View:视图
springmvc框架提供了很多的View视图类型的支持,包括:jstlView、freemarkerView、pdfView等。我们最常用的视图就是jsp。
一般情况下需要通过页面标签或页面模版技术将模型数据通过页面展示给用户,需要由程序员根据业务需求开发具体的页面。
SpringMVC拦截器
SpringMVC拦截器要实现HandlerInterceptor接口,包含三个方法:preHandle()、postHandle()、afterCompletion()。
开发拦截器:实现handlerInterceptor接口,重写三个接口方法。
注册拦截器:定义配置类,让它实现WebMvcConfigurer接口,在接口的addInterceptors方法中,注册拦截器,并定义该拦截器匹配哪些请求路径。
MVC拦截器 & Filter & AOP
- Filter:如果对所有的请求(包括静态资源)进行拦截,可以使用Filter;和框架无关,过滤器拦截的是URL,可以控制最初的http请求,但是更细一点的类和方法控制不了。
- Interceptor:SpringMVC一般是对Controller进行拦截的;拦截器拦截的也是URL,拦截器有三个方法,相对于过滤器更加细致,有被拦截逻辑执行前、后等。
- AOP: 如果对Controller外的其他bean进行拦截,可以使用SpringAOP;面向切面拦截的是类的元数据(包、类、方法名、参数等) 相对于拦截器更加细致,而且非常灵活,拦截器只能针对URL做拦截,而AOP针对具体的代码,能够实现更加复杂的业务逻辑。
| filter | interceptor | aop | |
|---|---|---|---|
| 使用方式 | 函数回调 | 反射机制 | 动态代理 |
| 使用场景 | 处理URL,过滤一些非法URL、非法字符, | 日志记录、权限检查 | 日志记录、性能监控、权限控制、缓存优化、事务管理(声明式事务) |
| 粒度 | 粗 | 中 | 细 |
Spring注解
@RequestMapping
@RequestMapping是用于处理请求地址映射的注解,请求地址为类地址和方法地址的拼接(如果类上没有该注解则直接为方法地址)。
参数
value:指定请求的实际地址,指定的地址可以是URI Template 模式;method: 指定请求的method类型, GET、POST、PUT、DELETE等;consumes: 指定处理请求的提交内容类型(Content-Type),例如application/json, text/html;produces: 指定返回的内容类型,仅当request请求头中的(Accept)类型中包含该指定类型才返回;params: 指定request中必须包含某些参数值时,才让该方法处理。headers: 指定request中必须包含某些指定的header值,才能让该方法处理请求。
在设置
value参数的时候,可能涉及的相关注解为:@PathVariable;
在设置params参数的时候,可能涉及的相关注解为:@RequestParam;
1 | |
@PathVariable
@PathVariable用来获得请求url中的动态参数,一般修饰于方法中的入参。
1 | |
@RequestParam
@RequestParam用于获取request请求的参数值。
1 | |
@ResponseBody & @RequestBody
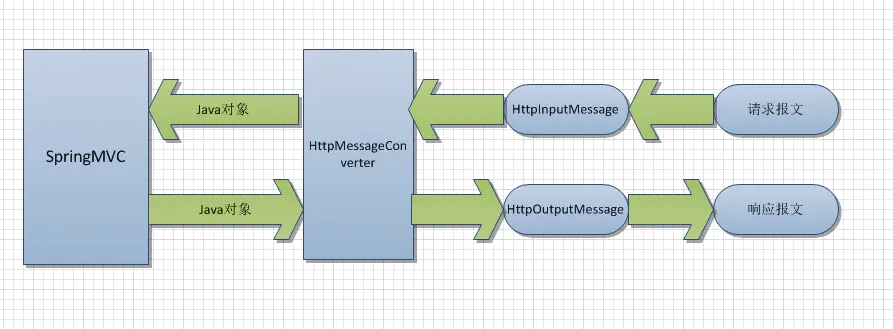
@ResponseBody用于将Controller的方法返回的对象,根据HTTP Request Header的Accept的内容,通过适当的HttpMessageConverter转换为指定格式后,写入到Response对象的body数据区。
@ResponseBody使用在返回的数据不是html标签的页面,而是其他某种格式的数据时(如json、xml等)使用.
@RequestBody用于将Controller的方法参数,根据HTTP Request Header的content-Type的内容,通过适当的HttpMessageConverter转换为JAVA类
@RequestBody使用在POST或者PUT的数据是JSON格式或者XML格式,而不是普通的键值对形式.
1 | |
@RestController
@RestController一般是使用在类上的,它表示的意思其实就是结合了@Controller和@ResponseBody两个注解,如果哪个类下的所有方法需要返回json数据格式的,就在哪个类上使用该注解,具有
@ResponseBody,一般是使用在单独的方法上的,需要哪个方法返回json数据格式,就在哪个方法上使用,具有针对性,统一性;
使用了@RestController注解之后,其本质相当于在该类的所有方法上都统一使用了@ResponseBody注解,所以该类下的所有方法都会返回json数据格式,输出在页面上,而不会再返回视图。
Spring MyBatis
问题整理
ORM
MyBatis属于半ORM框架,MyBatis并没有将java对象与数据库关联起来,而是将java方法和sql语句关联起来。
#{}和${}的区别
#{}是预编译处理,${}是字符串替换。
使用#{}设置参数,mybatis会创建一个预编译的sql,用?将#{}替换,在执行sql的时候,会通过PreparedStatement的set方法进行赋值;
使用${}设置参数,mybatis会直接将其替换成变量的值,然后执行sql。
使用预编译的方式可以提高sql执行效率,并且更加安全。
${}使用的一些特殊场景:根据不同条件生成不同的动态的列,然后根据列名排序,在传递列名的时候就不能用预编译的方式了。
Mapper接口绑定方式
- 通过注解:在接口的方法上面添加@Select@Update等注解,里面写上对应的SQL语句进行SQL语句的绑定。
- 通过xml文件绑定:通过配置文件的namespac标签指定对应的接口的全路径名
Mapper的CRUD配置属性
select:
- id
- parameterType:参数类型
- resultType/resultMap:返回类型
- useCache:二级缓存
- flushCache:刷新缓存
update/insert/delete:
- id
- parameterType
- flushCache
- statementType:Statement、PreparedStatement、CallableStatement
- timeout
一对多关联查询
通过collection标签实现。
- 首先在主表对应的实体类中增加集合的属性;
- 在mapper配置文件里,用select标签定义一个主表的查询方法,返回结果通过resultmap进行映射;
- 在collection标签里映射子表的属性,属性名property、集合元素类型javaType、实体类型ofType;
1 | |
缓存机制
mybatis有两级缓存。
一级缓存:默认启动,不能关闭;sqlsession级别;在同一个sqlsession中查询时,会根据方法和参数计算key,通过map查找和存储;
二级缓存:sqlsessionfactory级别;需要在全局配置settings中将cacheEnabled设为true;和命名空间绑定,需要在mapper中配置cache的标签。